
1. AI Tutorial¶
1.1. AidLux Introduction¶
AidLux is a complete set of edge-end AI development toolkit, which can simplify the environment deployment on the Qualcomm platform and help developers accelerate the implementation of AI applications.
We recommend using AidLux for the development of AI applications. AidLux includes components such as AidLite, AidGen, AidGenSE, and AidStream.
1.2. Install Requirements¶
Set AidLux apt source
# download public key
sudo wget -O- https://archive.aidlux.com/ubuntu24/public.key | gpg --dearmor | sudo tee /etc/apt/trusted.gpg.d/private-aidlux.gpg > /dev/null
# edit the source list
sudo vim /etc/apt/sources.list.d/private-aidlux.list
# add this line
deb [arch=arm64 signed-by=/etc/apt/trusted.gpg.d/private-aidlux.gpg] https://archive.aidlux.com/ubuntu24 noble main
# update apt cache
sudo apt update
Install AidLux requirements
# install these first
sudo apt install python3 python3-pip libopencv-dev python3-opencv net-tools
# install requirements
sudo apt install aidlux-aistack-base aidrtcm
sudo apt install aid-lms aidlms-sdk cmake aid-mms
# install DSP support
sudo apt-get install qcom-fastrpc1
sudo apt-get install qcom-fastrpc-dev
# install GPU support
sudo apt-add-repository -s ppa:ubuntu-qcom-iot/qcom-ppa
sudo apt install qcom-adreno-cl1
sudo ln -s /usr/lib/aarch64-linux-gnu/libOpenCL.so.1 /usr/lib/aarch64-linux-gnu/libOpenCL.so
# install aidlite-sdk and aidgen-sdk
sudo apt install aidlite-sdk aidlite-*
sudo apt install aidgen-qnn240-sdk
sudo apt-get install libfmt-dev nlohmann-json3-dev
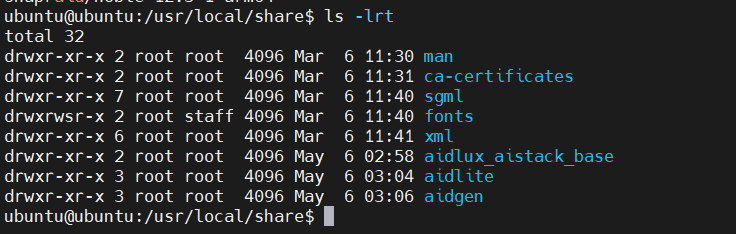
After installation, check /usr/local/share/, should have aidlite and aidgen there.
1.3. Model Farm¶
The Model Farm houses a large number of cutting-edge AI models that have been optimally adapted for use on Qualcomm NPU. Combined with the AidLux toolchain, it can help developers build their own AI applications more quickly on Qualcomm chips.
Addr: https://aiot.aidlux.com/en/models
Please visit Model Farm and register an account, which we will use in the following examples.
1.4. AidLite¶
AidLite is an AI execution framework designed to fully utilize the computing units (CPU, GPU, NPU) on the edge-side chips to accelerate the inference process of AI models.
Demos:
1.4.1. YOLOv8s¶
YOLOv8 is a cutting-edge, state-of-the-art (SOTA) model that builds upon the success of previous YOLO versions and introduces new features and improvements to further boost performance and flexibility. YOLOv8 is designed to be fast, accurate, and easy to use, making it an excellent choice for a wide range of object detection and tracking, instance segmentation, image classification and pose estimation tasks.
Use mms command to download yolov8s model, need Model Farm account.
# login, enter the account and password of the Model Farm according to the prompt.
mms login
# list and download model
mms list | grep YOLOv8s | grep FP16
mms get -m YOLOv8s -p fp16 -c iq9 -b qnn2.36 -d ./
# decompress
unzip YOLOv8s_iq9_fp16.zip
Navigate to model directory, follow the README to run:
cd ./code
python3 python/run_test.py --target_model ../models/IQ9/FP16/yolov8s_qcs9100_fp16.qnn236.ctx.bin --imgs ./python/bus.jpg --invoke_nums 10

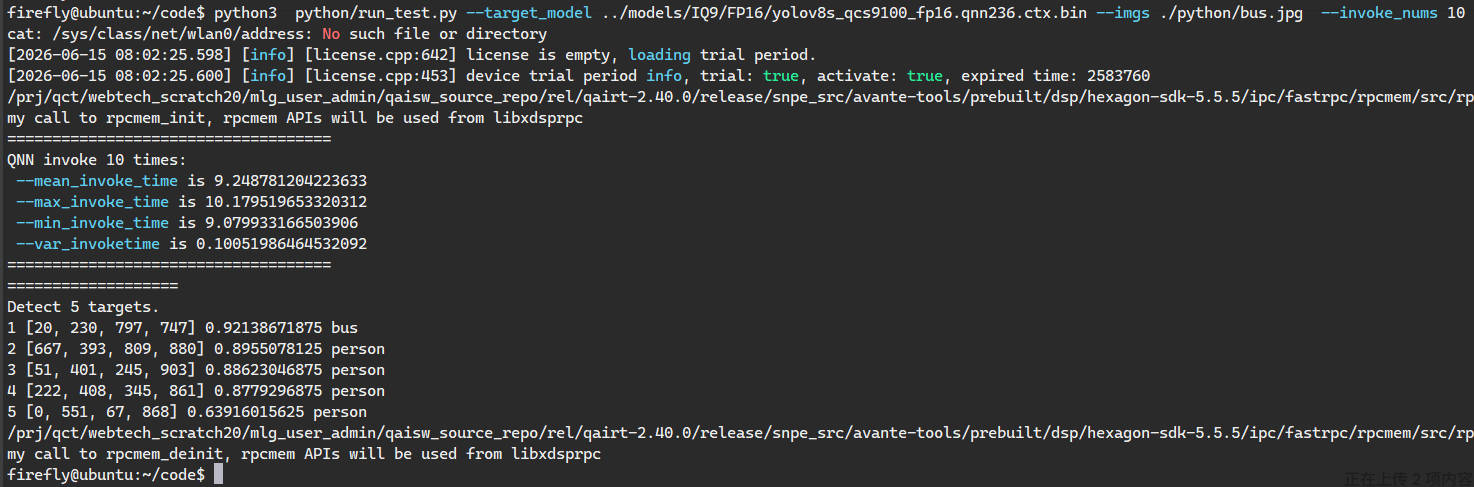
Check the result python/result.jpg

1.4.2. ControlNet¶
ControlNet is a neural framework designed to enhance control over generative models by incorporating conditional inputs like edge maps, depth data, or semantic segmentation. Proposed by Lvmin Zhang and Maneesh Agrawala, it integrates with diffusion models to enable precise control over image composition, object placement, and stylistic details via sketches, pose cues, or structural constraints. Widely used in digital art, design prototyping, film previsualization, and photo editing, it trains conditional encoders alongside base models to harmonize creative flexibility with structural guidance. The framework supports multi-modal inputs and real-time interaction, though challenges include stabilizing complex condition integration, optimizing computational overhead, and preventing overfitting.
Use mms command to download ControlNet model, need Model Farm account.
# login, enter the account and password of the Model Farm according to the prompt.
mms login
# list and download model
mms list | grep ControlNet | grep FP16
mms get -m ControlNet -p w8a16 -c qcs8550 -b qnn2.36 -d ./
unzip controlnet_qcs8550_qnn2.36_w8a16_aidlite.zip
Navigate to model directory, follow the README to run:
pip install transformers==5.1.0 diffusers==0.36.0
cd model_farm_controlnet_qcs8550_qnn2.36_w8a16_aidlite
python3 python/run_test.py

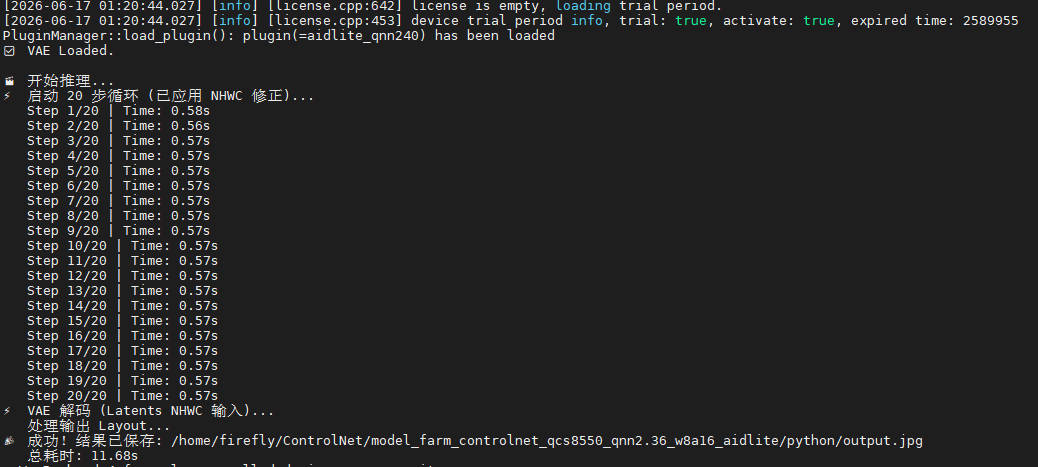
Check the result python/output.jpg

1.4.3. ConvNeXt-Tiny¶
ConvNeXt-Tiny is the lightweight version of the ConvNeXt model family, a modern convolutional neural network (CNN) designed to revamp traditional CNNs to compete with current popular Transformer models. ConvNeXt-Tiny retains the advantages of convolutional networks while incorporating design ideas from vision Transformers, such as deeper networks, larger convolution kernels, and LayerNorm. Compared to other models, ConvNeXt-Tiny has fewer parameters and lower computational demands but still provides efficient image classification performance, making it particularly suitable for resource-constrained environments like mobile devices or edge computing.
Use mms command to download ConvNeXt-Tiny model, need Model Farm account.
# login, enter the account and password of the Model Farm according to the prompt.
mms login
# list and download model
mms list | grep ConvNeXt-Tiny | grep FP16 | grep 8550
mms get -m ConvNeXt-Tiny -p FP16 -c QCS8550 -b qnn2.36 -d ./
unzip ConvNeXt-Tiny_qcs8550_fp16.zip
Navigate to model directory, follow the README to run:
cd ./code
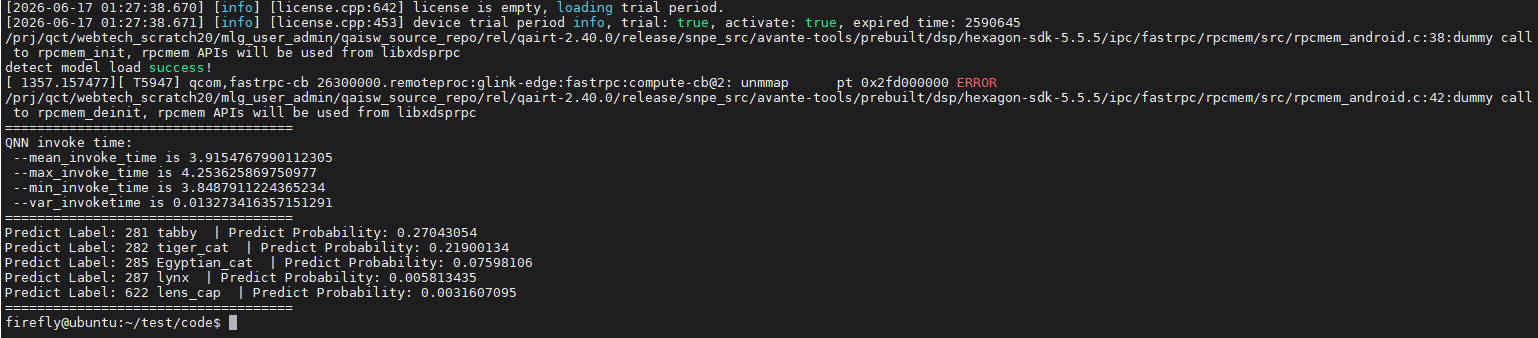
python3 python/run_test.py --target_model [model_file_path] --imgs ./python/tiger_cat.jpg --invoke_nums 10

1.4.4. Depth-Anything-V2-Small¶
Depth-Anything-V2 is a state-of-the-art foundation model for monocular depth estimation, designed to predict highly accurate depth information from a single RGB image. Compared to its predecessor, the V2 version significantly enhances the capture of fine-grained details and complex scenes by leveraging a more powerful teacher model (based on DINOv2-Giant) and a massive dataset of 595K synthetic and 62M+ pseudo-labeled real images. It demonstrates superior robustness when dealing with transparent objects, reflective surfaces, and low-light environments, while its optimized architecture enables inference speeds over 10x faster than diffusion-based models. With scales ranging from lightweight (25M) to giant (1.3B) parameters, Depth-Anything-V2 seamlessly adapts to diverse requirements, from real-time embedded applications to high-precision 3D reconstruction.
Use mms command to download Depth-Anything-V2-Small model, need Model Farm account.
# login, enter the account and password of the Model Farm according to the prompt.
mms login
# list and download model
mms list | grep Depth-Anything-V2-Small | grep FP16 | grep 8550
mms get -m Depth-Anything-V2-Small -p FP16 -c iq9 -b qnn2.36 -d ./
unzip Depth-Anything-V2-Small_iq9_fp16.zip
Navigate to model directory, follow the README to run:
pip install Pillow numpy matplotlib
cd code
cp python/* ./
python3 run_test.py


Check the result

1.4.5. FastSAM-S¶
The Fast Segment Anything Model (FastSAM) is a novel, real-time CNN-based solution for the Segment Anything task. This task is designed to segment any object within an image based on various possible user interaction prompts. FastSAM significantly reduces computational demands while maintaining competitive performance, making it a practical choice for a variety of vision tasks.
Use mms command to download FastSAM-S model, need Model Farm account.
# login, enter the account and password of the Model Farm according to the prompt.
mms login
# list and download model
mms list | grep FastSAM-S | grep FP16
mms get -m FastSAM-S -p FP16 -c iq9 -b qnn2.36 -d ./
unzip FastSAM-S_iq9_fp16.zip
Navigate to model directory, follow the README to run:
cd code
python3 python/run_test.py --target_model ../models/IQ9/FP16/cutoff_fastsam_s_qcs9100_fp16.qnn236.ctx.bin --imgs python/dogs.jpg --invoke_nums 10

Check the result

1.4.6. YOLO11l-Pose¶
YOLO11 pose represents the latest pinnacle of pose estimation technology from Ultralytics, offering a comprehensive suite of models ranging from the ultra-lightweight (Nano) to the high-precision (Extra-Large). This series features an entirely redesigned backbone and neck architecture, leveraging enhanced C3k2 modules and C2PSA mechanisms to achieve a significant breakthrough on the accuracy-speed Pareto frontier. Compared to its predecessors, it captures complex human poses with higher fidelity and maintains stable keypoint tracking even under severe occlusion. With its versatile scalability, YOLO11 pose provides an optimal 2D keypoint detection solution for both latency-sensitive edge computing and high-performance offline analytical tasks demanding state-of-the-art precision.
Use mms command to download YOLO11l-Pose model, need Model Farm account.
# login, enter the account and password of the Model Farm according to the prompt.
mms login
# list and download model
mms list | grep YOLO11l-Pose | grep FP16
mms get -m YOLO11l-Pose -p FP16 -c iq9 -b qnn2.36 -d ./
unzip YOLO11l-Pose_iq9_fp16.zip
Navigate to model directory, follow the README to run:
cd code
python3 python/run_test.py --target_model ../models/IQ9/FP16/yolo11l-pose_qcs9100_fp16.qnn236.ctx.bin --imgs python/bus.jpg --invoke_nums 10


Check the result

1.4.7. YOLO11s-obb¶
YOLO11s-obb is a lightweight oriented bounding box (OBB) detection model in the YOLO family, adapted to efficiently detect rotated objects. It is designed for embedded and mobile deployments with limited computational resources.
Key Features:
Anchor-Free Design: Simplifies the model architecture and speeds up inference;
Orientation-Aware Head: Predicts rotation angles along with bounding boxes and classes, enabling accurate detection of rotated objects like drones, vehicles, road signs, and text regions;
Lightweight Backbone: Combines a compact backbone with orientation detection modules to keep parameter count and computation low, allowing near real-time performance;
Wide Applicability: Ideal for use cases such as drone imagery analysis, industrial part inspection, and map element detection where object orientation matters.
Use mms command to download YOLO11s-obb model, need Model Farm account.
# login, enter the account and password of the Model Farm according to the prompt.
mms login
# list and download model
mms list | grep YOLO11s-obb | grep FP16 | grep 8550
mms get -m YOLO11s-obb -p FP16 -c QCS8550 -b qnn2.36 -d ./
unzip YOLO11s-obb_qcs8550_fp16.zip
Navigate to model directory, follow the README to run:
cd code
sudo python3 python/run_test.py --target_model ../models/QCS8550/FP16/yolo11s-obb_qcs8550_fp16.qnn236.ctx.bin --imgs python/boats.jpg --invoke_nums 10

Check the result

1.5. AidGen¶
AidGen is a dedicated inference framework for generative Transformer models, built based on AidLite. Its purpose is to fully utilize the various computing units (CPU, GPU, NPU) of the hardware to achieve inference acceleration for large models on the edge side.
AidGen offers an atomic-level large model inference interface, which is suitable for developers to integrate large model inference into their own applications.
AidGen supports:
Large Language Model -> AidLLM
Multimodal Large Models -> AidMLM
Demos:
1.5.1. MiniCPM5-1B¶
MiniCPM5-1B is the first checkpoint in the MiniCPM5 series. It is designed for local assistants, coding agents, tool-use workflows, and reasoning scenarios where a compact model is preferred. The model keeps a small deployment footprint while providing native long-context support and both Think / No Think chat modes through the same checkpoint.
Use mms command to download MiniCPM5 model, need Model Farm account.
# login, enter the account and password of the Model Farm according to the prompt.
mms login
# list and download model
mms list | grep MiniCPM5
mms get -m MiniCPM5-1B -p W4A16 -c iq9 -b qnn2.36 -d ./
Decompress
mkdir MiniCPM5-1B-aidllm
unzip qnn236_qcs9075_cl4096.zip -d MiniCPM5-1B-aidllm/
Create a model configuration file config.json
cd ./MiniCPM5-1B-aidllm/qnn236_qcs9075_cl4096
vim config.json
The contents of configuration file:
{
"backend_type" : "genie",
"prefix_path":"kv-cache.primary.qnn-htp",
"model":{
"path" : [
"minicpm5-1b_qnn236_qcs9075_cl4096_1_of_3.aidem",
"minicpm5-1b_qnn236_qcs9075_cl4096_2_of_3.aidem",
"minicpm5-1b_qnn236_qcs9075_cl4096_3_of_3.aidem"
]
}
}
Copy the demo project to model directory then build the demo
# copy demo project to model directory
cp -r /usr/local/share/aidgen/examples/aidgen_qnn240/cpp/aidllm/ ./
# build
cd ./aidllm
mkdir build && cd build
cmake ..
make
Run the demo
cd ../../
./aidllm/build/test_aidllm abort ./config.json
1.5.2. Qwen3-8B-CL8192¶
Qwen3 is the latest generation of large language models in Qwen series, offering a comprehensive suite of dense and mixture-of-experts (MoE) models. Built upon extensive training, Qwen3 delivers groundbreaking advancements in reasoning, instruction-following, agent capabilities, and multilingual support, with the following key features:
Uniquely support of seamless switching between thinking mode (for complex logical reasoning, math, and coding) and non-thinking mode (for efficient, general-purpose dialogue) within single model, ensuring optimal performance across various scenarios.
Significantly enhancement in its reasoning capabilities, surpassing previous QwQ (in thinking mode) and Qwen2.5 instruct models (in non-thinking mode) on mathematics, code generation, and commonsense logical reasoning.
Superior human preference alignment, excelling in creative writing, role-playing, multi-turn dialogues, and instruction following, to deliver a more natural, engaging, and immersive conversational experience.
Expertise in agent capabilities, enabling precise integration with external tools in both thinking and unthinking modes and achieving leading performance among open-source models in complex agent-based tasks.
Support of 100+ languages and dialects with strong capabilities for multilingual instruction following and translation.
Use mms command to download Qwen3 model, need Model Farm account.
# login, enter the account and password of the Model Farm according to the prompt.
mms login
# list and download model
mms list | grep Qwen3
mms get -m Qwen3-8B-CL8192 -p W4A16 -c iq9 -b qnn2.36 -d ./
Decompress
mkdir qwen3-8b-aidllm
unzip qnn236_qcs9075_cl8192.zip -d qwen3-8b-aidllm/
Create a model configuration file qwen3-8b-encrypt.json
cd ./qwen3-8b-aidllm/qnn236_qcs9075_cl8192
vim qwen3-8b-encrypt.json
The contents of configuration file:
{
"backend_type" : "genie",
"prefix_path":"kv-cache.primary.qnn-htp",
"model":{
"path" : [
"qwen3-8b_qnn236_qcs9075_cl8192_1_of_5.serialized.bin.aidem",
"qwen3-8b_qnn236_qcs9075_cl8192_2_of_5.serialized.bin.aidem",
"qwen3-8b_qnn236_qcs9075_cl8192_3_of_5.serialized.bin.aidem",
"qwen3-8b_qnn236_qcs9075_cl8192_4_of_5.serialized.bin.aidem",
"qwen3-8b_qnn236_qcs9075_cl8192_5_of_5.serialized.bin.aidem"
]
}
}
Copy the demo project to model directory then build the demo
# copy demo project to model directory
cp -r /usr/local/share/aidgen/examples/aidgen_qnn240/cpp/aidllm/ ./
# build
cd ./aidllm
mkdir build && cd build
cmake ..
make
Run the demo
cd ../../
./aidllm/build/test_aidllm abort ./qwen3-8b-encrypt.json
1.5.3. Meta-Llama-3.1-8B-Instruct¶
The Meta Llama 3.1 collection of multilingual large language models (LLMs) is a collection of pretrained and instruction tuned generative models in 8B, 70B and 405B sizes (text in/text out). The Llama 3.1 instruction tuned text only models (8B, 70B, 405B) are optimized for multilingual dialogue use cases and outperform many of the available open source and closed chat models on common industry benchmarks.
Use mms command to download Meta-Llama model, need Model Farm account.
# login, enter the account and password of the Model Farm according to the prompt.
mms login
# list and download model
mms list | grep Meta-Llama
mms get -m Meta-Llama-3.1-8B-Instruct -p W4A16 -c iq9 -b qnn2.40 -d ./
Decompress
mkdir Meta-Llama-3.1-8B-aidllm
unzip qnn240_qcs9075_cl4096.zip -d Meta-Llama-3.1-8B-aidllm
Copy the demo project to model directory, and modify the template
# copy demo project to model directory
cd Meta-Llama-3.1-8B-aidllm/qnn240_qcs9075_cl4096
cp -r /usr/local/share/aidgen/examples/aidgen_qnn240/cpp/aidllm/ ./
# modify the template
cd ./aidllm
vim test_aidllm.cpp
# change the "prompt_template" in line 48 to this:
prompt_template = "<|begin_of_text|><|start_header_id|>system<|end_header_id|>\nYou are a pirate chatbot who always responds in pirate speak!<|eot_id|><|start_header_id|>user<|end_header_id|>\n{0}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n";
# build
mkdir build && cd build
cmake ..
make
Run the demo
cd ../../
./aidllm/build/test_aidllm multi_turn ./Meta-Llama-3.1-8B-Instruct-htp.json
1.5.4. Gemma-2-2B-it¶
Gemma is a family of lightweight, state-of-the-art open models from Google, built from the same research and technology used to create the Gemini models. They are text-to-text, decoder-only large language models, available in English, with open weights for both pre-trained variants and instruction-tuned variants. Gemma models are well-suited for a variety of text generation tasks, including question answering, summarization, and reasoning. Their relatively small size makes it possible to deploy them in environments with limited resources such as a laptop, desktop or your own cloud infrastructure, democratizing access to state of the art AI models and helping foster innovation for everyone.
Use mms command to download Gemma model, need Model Farm account.
# login, enter the account and password of the Model Farm according to the prompt.
mms login
# list and download model
mms list | grep Gemma
mms get -m Gemma-2-2B-it -p W4A16 -c qcs8550 -b qnn2.29 -d ./
Decompress
mkdir -p Gemma-2-2B-aidllm
unzip qnn229_qcs8550_cl4096.zip -d Gemma-2-2B-aidllm/
Copy the demo project to model directory, and modify the template
# copy demo project to model directory
cd Gemma-2-2B-aidllm/qnn229_qcs8550_cl4096
cp -r /usr/local/share/aidgen/examples/aidgen_qnn240/cpp/aidllm/ ./
# modify the template
cd ./aidllm
vim test_aidllm.cpp
# change the "prompt_template" in line 48 to this:
prompt_template = "<bos><start_of_turn>user\n{0}<end_of_turn>\n<start_of_turn>model";
# build
mkdir build && cd build
cmake ..
make
Run the demo
cd ../../
./aidllm/build/test_aidllm abort ./gemma-2-2b-it-htp.json
1.5.5. Falcon3-7B-Instruct¶
Falcon3 family of Open Foundation Models is a set of pretrained and instruct LLMs ranging from 1B to 10B.
This repository contains the Falcon3-7B-Instruct. It achieves state of art results (at the time of release) on reasoning, language understanding, instruction following, code and mathematics tasks. Falcon3-7B-Instruct supports 4 languages (english, french, spanish, portuguese) and a context length up to 32K.
Use mms command to download Falcon model, need Model Farm account.
# login, enter the account and password of the Model Farm according to the prompt.
mms login
# list and download model
mms list | grep Falcon
mms get -m Falcon3-7B-Instruct -p W4A16 -c qcs8550 -b qnn2.38 -d ./
Decompress
mkdir -p Falcon3-7B-aidllm
unzip qnn237_qcs8550_cl4096.zip -d Falcon3-7B-aidllm/
Copy the demo project to model directory, and modify the template
# copy demo project to model directory
cd Falcon3-7B-aidllm/qnn237_qcs8550_cl4096
cp -r /usr/local/share/aidgen/examples/aidgen_qnn240/cpp/aidllm/ ./
# modify the template
cd ./aidllm
vim test_aidllm.cpp
# change the "prompt_template" in line 48 to this:
prompt_template = "<|system|>\nYou are a helpful friendly assistant Falcon3 from TII, try to follow instructions as much as possible.\n<|user|>\n{0}\n<|assistant|>\n";
# build
mkdir build && cd build
cmake ..
make
Run the demo
cd ../../
./aidllm/build/test_aidllm abort ./falcon3-7b-instruct-htp.json
1.5.6. DeepSeek-R1-Distill-Qwen-7B¶
To address the issues if DeepSeek-R1-Zero and further enhance reasoning performance, DeepSeek introduce DeepSeek-R1, which incorporates cold-start data before RL. DeepSeek-R1 achieves performance comparable to OpenAI-o1 across math, code, and reasoning tasks. To support the research community, DeepSeek have open-sourced DeepSeek-R1-Zero, DeepSeek-R1, and six dense models distilled from DeepSeek-R1 based on Llama and Qwen. DeepSeek-R1-Distill-Qwen-32B outperforms OpenAI-o1-mini across various benchmarks, achieving new state-of-the-art results for dense models.
Use mms command to download DeepSeek model, need Model Farm account.
# login, enter the account and password of the Model Farm according to the prompt.
mms login
# list and download model
mms list | grep DeepSeek
mms get -m DeepSeek-R1-Distill-Qwen-7B -p W4A16 -c QCS8550 -b qnn2.29 -d ./
Decompress
mkdir -p DeepSeek-R1-Distill-Qwen-7B-aidllm
unzip qnn229_qcs8550_cl4096.zip -d DeepSeek-R1-Distill-Qwen-7B-aidllm
Copy the demo project to model directory, and modify the template
# copy demo project to model directory
cd DeepSeek-R1-Distill-Qwen-7B-aidllm/qnn229_qcs8550_cl4096
cp -r /usr/local/share/aidgen/examples/aidgen_qnn240/cpp/aidllm/ ./
# modify the template
cd ./aidllm
vim test_aidllm.cpp
# change the "prompt_template" in line 48 to this:
prompt_template = "<|begin▁of▁sentence|>You are Deepseek-R1, an AI assistant created exclusively by the Chinese Company DeepSeek. You'll provide helpful, harmless, and detailed responses to all user inquiries.<|User|>Introduce Qualcomm in 100 words<|Assistant|>"
# build
mkdir build && cd build
cmake ..
make
Run the demo
cd ../../
./aidllm/build/test_aidllm multi_turn DeepSeek-R1-Distill-Qwen-7B-htp.json
1.5.7. Phi-3.5-mini-instruct¶
Phi-3.5-mini is a lightweight, state-of-the-art open model built upon datasets used for Phi-3 - synthetic data and filtered publicly available websites - with a focus on very high-quality, reasoning dense data. The model belongs to the Phi-3 model family and supports 128K token context length. The model underwent a rigorous enhancement process, incorporating both supervised fine-tuning, proximal policy optimization, and direct preference optimization to ensure precise instruction adherence and robust safety measures.
Use mms command to download Phi model, need Model Farm account.
# login, enter the account and password of the Model Farm according to the prompt.
mms login
# list and download model
mms list | grep Phi-3.5
mms get -m Phi-3.5-mini-instruct -p W4A16 -c QCS8550 -b qnn2.29 -d ./
Decompress
mkdir -p Phi-3.5-mini-aidllm
unzip qnn229_qcs8550_cl4096.zip -d Phi-3.5-mini-aidllm
Copy the demo project to model directory, and modify the template
# copy demo project to model directory
cd Phi-3.5-mini-aidllm/qnn229_qcs8550_cl4096
cp -r /usr/local/share/aidgen/examples/aidgen_qnn240/cpp/aidllm/ ./
# modify the template
cd ./aidllm
vim test_aidllm.cpp
# change the "prompt_template" in line 48 to this:
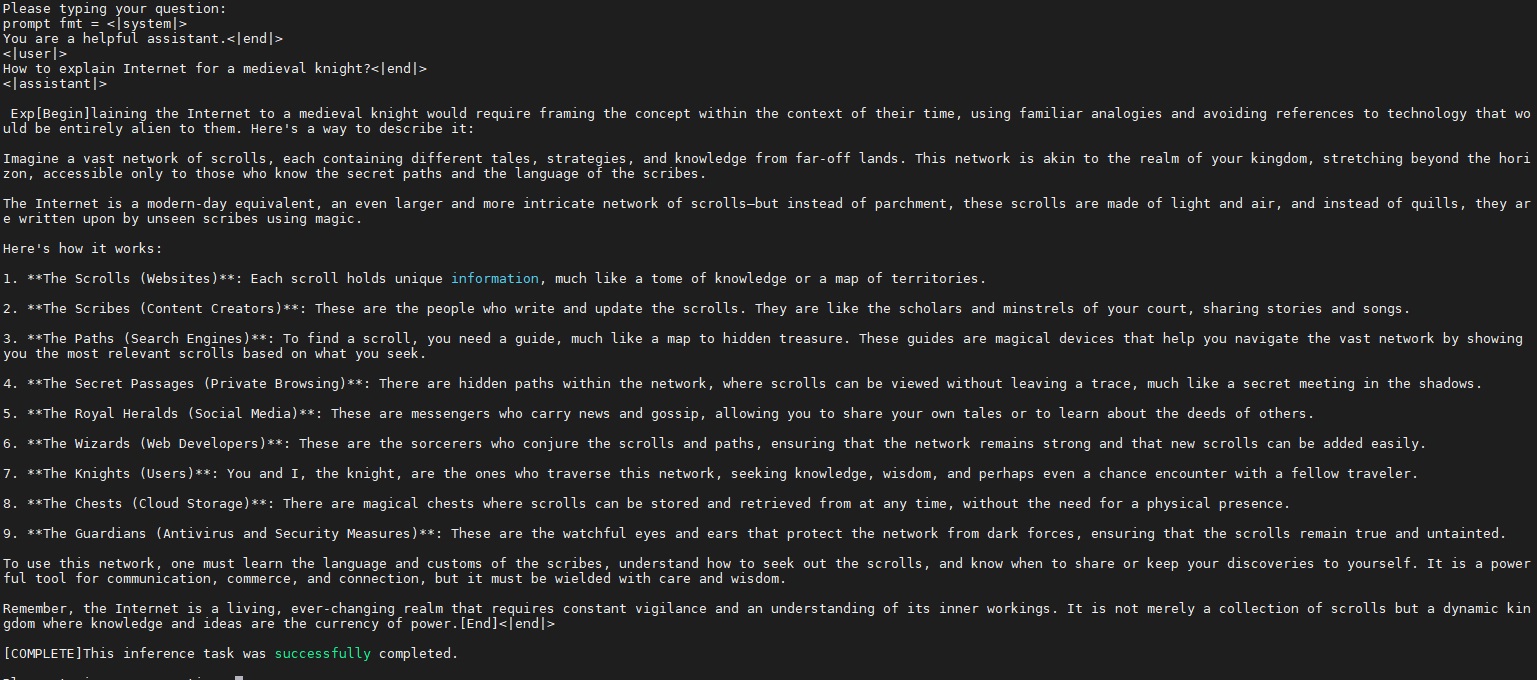
prompt_template = "<|system|>\nYou are a helpful assistant.<|end|>\n<|user|>\nHow to explain Internet for a medieval knight?<|end|>\n<|assistant|>\n"
# build
mkdir build && cd build
cmake ..
make
Run the demo
cd ../../
./aidllm/build/test_aidllm multi_turn Phi-3.5-mini-instruct-htp.json
1.5.8. HY-MT1.5-1.8B¶
Hunyuan Translation Model Version 1.5 includes a 1.8B translation model, HY-MT1.5-1.8B, and a 7B translation model, HY-MT1.5-7B. Both models focus on supporting mutual translation across 33 languages and incorporating 5 ethnic and dialect variations. Among them, HY-MT1.5-7B is an upgraded version of WMT25 championship model, optimized for explanatory translation and mixed-language scenarios, with newly added support for terminology intervention, contextual translation, and formatted translation. Despite having less than one-third the parameters of HY-MT1.5-7B, HY-MT1.5-1.8B delivers translation performance comparable to its larger counterpart, achieving both high speed and high quality. After quantization, the 1.8B model can be deployed on edge devices and support real-time translation scenarios, making it widely applicable.
Use mms command to download HY-MT model, need Model Farm account.
# login, enter the account and password of the Model Farm according to the prompt.
mms login
# list and download model
mms list | grep HY-MT
mms get -m HY-MT1.5-1.8B -p w4a16 -c iq9 -b qnn2.36 -d ./
Decompress
mkdir HY-MT1.5-1.8B-aidllm
unzip qnn236_qcs9075_cl2048.zip -d HY-MT1.5-1.8B-aidllm
Create a model configuration file config.json
cd HY-MT1.5-1.8B-aidllm/qnn236_qcs9075_cl2048/
vim config.json
The contents of configuration file:
{
"backend_type" : "genie",
"prefix_path":"kv-cache.primary.qnn-htp",
"model":{
"path" : [
"hy-mt1.5-1.8b_qnn236_qcs9075_cl2048_1_of_2.serialized.bin.aidem",
"hy-mt1.5-1.8b_qnn236_qcs9075_cl2048_2_of_2.serialized.bin.aidem"
]
}
}
Copy the demo project to model directory, and modify the template
# copy demo project to model directory
cp -r /usr/local/share/aidgen/examples/aidgen_qnn240/cpp/aidllm/ ./
# modify the template
cd ./aidllm
vim test_aidllm.cpp
# change the "prompt_template" in line 48 to this:
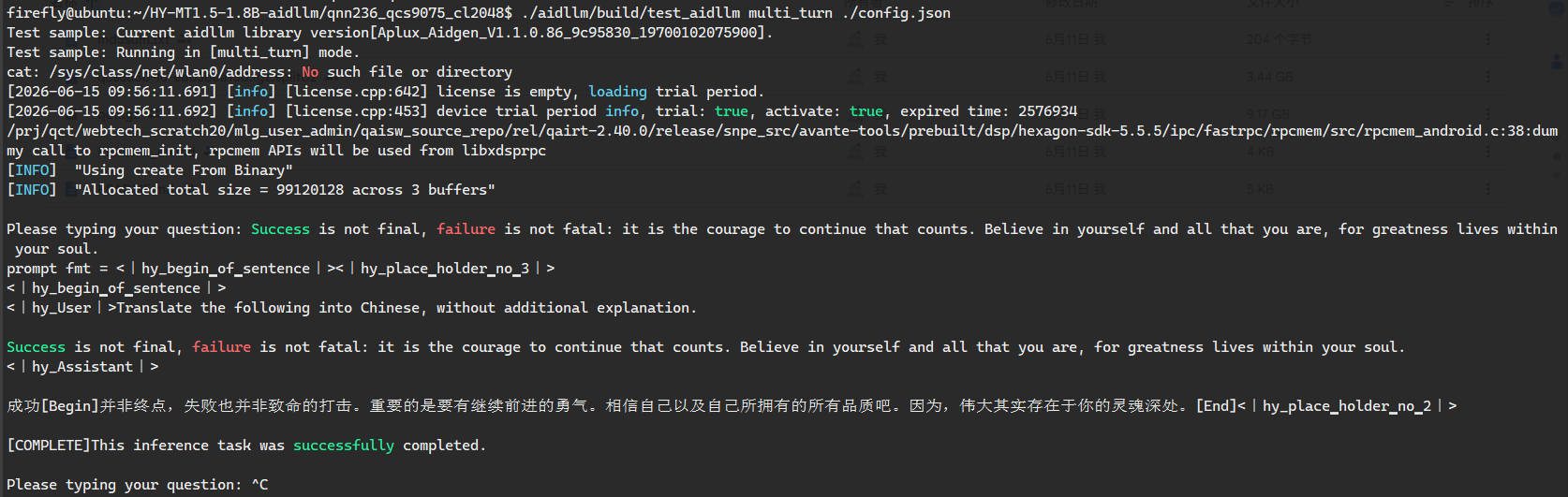
prompt_template = "<|hy_begin▁of▁sentence|><|hy_place▁holder▁no▁3|>\n<|hy_begin▁of▁sentence|>\n<|hy_User|>Translate the following into Chinese, without additional explanation.\n\n{0}\n<|hy_Assistant|>\n";
# build
mkdir build && cd build
cmake ..
make
Run the demo
cd ../../
./aidllm/build/test_aidllm multi_turn ./config.json
1.5.9. Qwen2.5-VL-3B-Instruct¶
Qwen2.5-VL is the enhanced version of Qwen2-VL vision-language models. Key Enhancements:
Understand things visually: Qwen2.5-VL is not only proficient in recognizing common objects such as flowers, birds, fish, and insects, but it is highly capable of analyzing texts, charts, icons, graphics, and layouts within images.
Being agentic: Qwen2.5-VL directly plays as a visual agent that can reason and dynamically direct tools, which is capable of computer use and phone use.
Understanding long videos and capturing events: Qwen2.5-VL can comprehend videos of over 1 hour, and this time it has a new ability of cpaturing event by pinpointing the relevant video segments.
Capable of visual localization in different formats: Qwen2.5-VL can accurately localize objects in an image by generating bounding boxes or points, and it can provide stable JSON outputs for coordinates and attributes.
Generating structured outputs: for data like scans of invoices, forms, tables, etc. Qwen2.5-VL supports structured outputs of their contents, benefiting usages in finance, commerce, etc.
Use mms command to download Qwen3 model, need Model Farm account.
# login, enter the account and password of the Model Farm according to the prompt
mms login
# list and download model
mms list | grep Qwen2 | grep VL
mms get -m 'Qwen2.5-VL-3B-Instruct (392x392)' -p w4a16 -c qcs8550 -b qnn2.36 -d ./
Decompress
mkdir qwen2.5-vl-aidmlm
unzip qnn236_qcs8550_cl2048.zip -d ./qwen2.5-vl-aidmlm/
Create a model configuration file Qwen2.5-VL-3B-392x392-8550.json
cd ./qwen2.5-vl-aidmlm/qnn236_qcs8550_cl2048/
vim Qwen2.5-VL-3B-392x392-8550.json
The contents of configuration file:
{
"vision_model_path": "./veg.serialized.bin.aidem",
"pos_embed_cos_path": "./position_ids_cos.raw",
"pos_embed_sin_path": "./position_ids_sin.raw",
"vocab_embed_path": "./embedding_weights_151936x2048.raw",
"window_attention_mask_path": "./window_attention_mask.raw",
"full_attention_mask_path": "./full_attention_mask.raw",
"llm_path_list": [
"./qwen2p5-vl-3b_qnn236_qcs8550_cl2048_1_of_1.serialized.bin.aidem"
]
}
Copy demo project to model directory then build the demo
# copy demo project to model directory
cp -r /usr/local/share/aidgen/examples/aidgen_qnn240/cpp/aidmlm/* ./
# build
mkdir build && cd build
cmake ..
make
Run the demo
cd ..
./build/test_aidmlm single qwen25vl3b392 Qwen2.5-VL-3B-392x392-8550.json /home/ubuntu/dog.jpg "Describe the scene in the picture."

1.6. AidGenSE¶
AidGenSE is a generative AI HTTP service that is based on AidGen and has been adapted to the OpenAI HTTP protocol. Developers can call the generative AI through HTTP and quickly integrate it into their own applications.
The following is an introduction to the usage of AidGenSE:
Prepare AidGenSE environment
# setup python virtual env
sudo apt install -y python3-pip python3-venv > /dev/null 2>&1
sudo python3 -m venv /opt/aidlux/aid-python3
# create aid-python3 command
echo '#!/bin/bash
exec /opt/aidlux/aid-python3/bin/python3 "$@"' | sudo tee /usr/bin/aid-python3 > /dev/null
sudo chmod +x /usr/bin/aid-python3
# create aid-pip3 command
echo '#!/bin/bash
exec /opt/aidlux/aid-python3/bin/python3 -m pip "$@"' | sudo tee /usr/bin/aid-pip3 > /dev/null
sudo chmod +x /usr/bin/aid-pip3
# install AidGenSE
sudo apt install aidgense
sudo aidllm system --sys linux --soc 8550
sudo apt install aid-pkg
Common instructions
# list available models
sudo aidllm remote-list api
# download model
sudo aidllm pull api aplux/Qwen3-8B-8550-cl2048
# list downloaded models
sudo aidllm list api
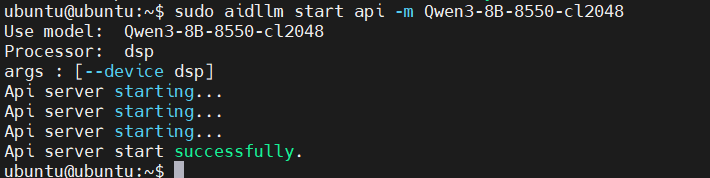
# start model api
sudo aidllm start api
# stop model api
sudo aidllm stop api
After “start api”, you can use OpenAI HTTP requests to interact with AI model through
:8888
1.7. AidStream¶
AidStream is a multimedia data real-time processing toolkit based on GStreamer, suitable for building AI-based video and image analysis applications and services.
Demo:
Install requirements
sudo apt-add-repository -s ppa:ubuntu-qcom-iot/qcom-ppa
sudo apt update
sudo apt install weston-autostart
sudo apt install gstreamer1.0-qcom-sample-apps
sudo reboot # need reboot once
sudo apt-get install libgstreamer1.0-dev gstreamer1.0-plugins-ugly gstreamer1.0-libav gstreamer1.0-alsa gstreamer1.0-gtk3
sudo apt-get install -y libjsoncpp-dev
sudo ln -s /usr/lib/aarch64-linux-gnu/libjsoncpp.so /usr/lib/aarch64-linux-gnu/libjsoncpp.so.1
sudo apt install gstreamer1.0-rtsp
sudo apt install aidstream-gst
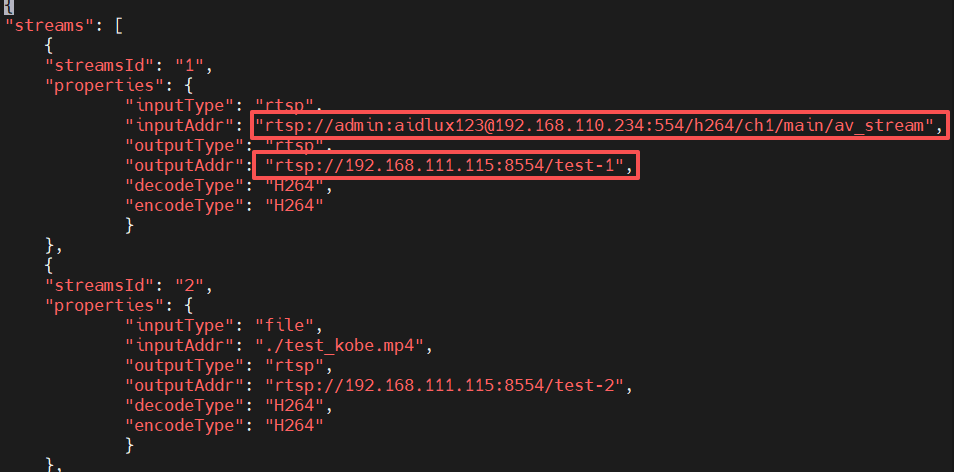
Configure video stream input and output addresses.
cd /usr/local/share/aidstream-gst/conf
# modify the input and output addresses to available video stream server addresses.
vim aidstream-gst.conf
Run the demo
mkdir aid-streamer-gst
cd aid-streamer-gst
cp -r /usr/local/share/aidstream-gst/example/ ./
cd example/python
sudo python3 example.py
Use the output address to check the result.