1. NPU开发简介¶
1.1. 前言¶
| 板子 | OS | NPU 连接方式 | RKNPU 支持版本 | RKNN Toolkit (Lite) 支持版本 |
|---|---|---|---|---|
| AIO-3399Pro-JD4 | Linux | USB3.0 | 1.7.1 | 1.7.1 |
| AIO-3399ProC | Linux | PCIE | 1.7.1 | 1.7.1 |
AIO-3399ProC 开发者需要注意:
NPU推理阶段会与CPU进行数据通信,单次传输数据量少但频率高,但是与USB3.0相比PCIE不适合小文件传输。所以导致使用 “PCIE连接的NPU” 会比使用 “USB3.0方式连接的NPU” 在实际推理速度上慢很多。为了解决这个问题,我们制作了相关PCIE-NPU加速补丁,最终结果是推理速度追平“USB3.0方式连接的NPU”,具体使用方法和注意事项请查看补丁注释。
注意:PCIE-NPU加速补丁默认没有启用,具体启用方法和注意事项请查看补丁注释。
PCIE-NPU加速补丁 https://gitlab.com/firefly-linux/kernel/-/commit/892d398b3830c1e1b0560167f1896f38bd7e084a
确认是否启用了PCIE-NUP加速补丁 开发者可以通过以下4个测试项测试是否已经启动了PCIE-NUP加速补丁:
系统能正常启动
NPU驱动版本不小于1.7.1
dpkg -l |grep firefly-3399pronpu-driver
查看PCIE_RK1808_OPTIMIZATION的状态为okay
cat /sys/firmware/devicetree/base/PCIE_RK1808_OPTIMIZATION/status
NPU使用无报错
1.2. NPU特性¶
支持 8bit/16bit 运算,运算性能高达 3.0TOPS。
相较于 GPU 作为 AI 运算单元的大型芯片方案,功耗不到 GPU 所需要的 1%。
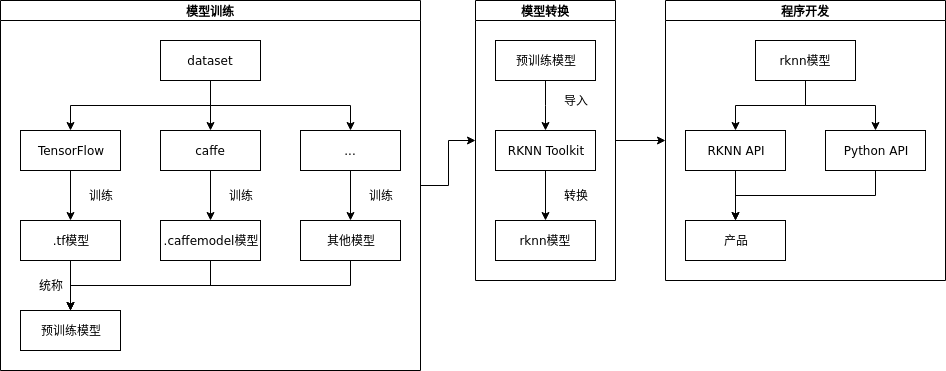
可直接加载 Caffe / Mxnet / TensorFlow 模型。
提供 AI 开发工具:支持模型快速转换、支持开发板端侧转换 API、支持 TensorFlow / TF Lite / Caffe / ONNX / Darknet 等模型 。
提供 AI 应用开发接口:支持 Android NN API、提供 RKNN 跨平台 API、Linux 支持 TensorFlow 开发。