1. NPU Brief Introduction to Development¶
1.1. Preface¶
| BOARD | OS | NPU connection method | RKNPU supported version | RKNN Toolkit (Lite) Supported Versions |
|---|---|---|---|---|
| AIO-3399Pro-JD4 | Linux | USB3.0 | 1.7.1 | 1.7.1 |
| AIO-3399ProC | Linux | PCIE | 1.7.1 | 1.7.1 |
AIO-3399ProC developers need to pay attention:
The NPU inference stage will communicate with the CPU. The amount of data transmitted in a single transmission is small but the frequency is high. However, compared with USB3.0, PCIE is not suitable for small file transmission. Therefore, using the “PCIE-connected NPU” will be much slower in actual inference speed than using the “USB3.0-connected NPU”. In order to solve this problem, we have made related PCIE-NPU acceleration patches, and the final result is that the inference speed is equal to the “NPU connected by USB3.0”. Please refer to the patch notes for specific usage and precautions.
Note: The PCIE-NPU acceleration patch is not enabled by default. Please refer to the patch notes for specific enabling methods and precautions.
PCIE-NPU acceleration patch https://gitlab.com/firefly-linux/kernel/-/commit/892d398b3830c1e1b0560167f1896f38bd7e084a
Confirm whether the PCIE-NUP acceleration patch is enabled Developers can test whether the PCIE-NUP acceleration patch has been activated through the following four test items:
The system can start normally
NPU driver version not less than 1.7.1
dpkg -l |grep firefly-3399pronpu-driver
Check that the status of PCIE_RK1808_OPTIMIZATION is okay
cat /sys/firmware/devicetree/base/PCIE_RK1808_OPTIMIZATION/status
No error reported when using NPU
1.2. NPU Characteristics¶
Supports 8 bit/16 bit operation with 3.0 TOPS performance
Compared with the large chip scheme of GPU as AI computing unit, the power consumption of GPU is less than 1%.
Could load Caffe / Mxnet / TensorFlow model Directly
Provide AI development tools: support rapid model transformation, development board end-to-side conversion API, TensorFlow / TF Lite / Caffe / ONNX / Darknet and other models
Provide AI application development interface: support Android NN API, RKNN cross-platform API, Linux support TensorFlow development
1.3. Process¶
The complete NPU development process is shown in the following figure
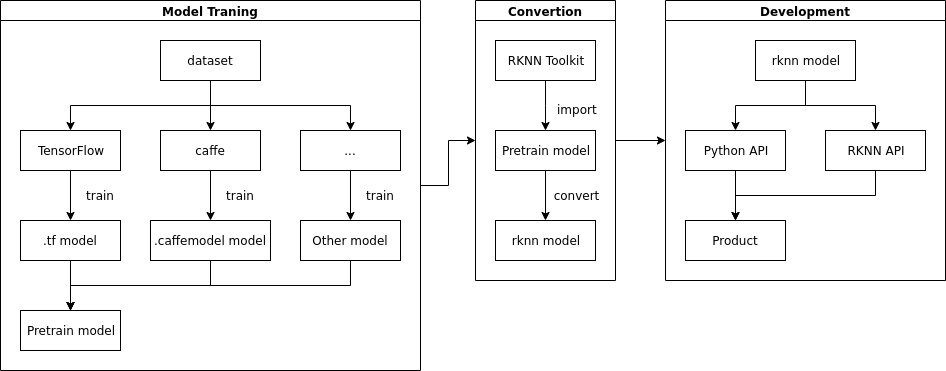
1.3.1. 1. model training¶
In the model training stage, users choose the appropriate framework (such as Caffe, TensorFlow, etc.) according to the needs and actual conditions to train to get the model that meets the needs. The trained model can also be used directly.
1.3.2. 2. Model transformation¶
In this stage, the model obtained from model training is transformed into the model available to NPU through RKNN Toolkit.
1.3.3. 3. Program Development¶
The last stage is to implement business logic for Python API development program based on RKNN API or RKNN Tookit
This document mainly introduces model transformation and RKNN-based program development, and does not involve the content of model training.